Full-size: PNG, PDF (print on 11x17" paper).
|
|
|
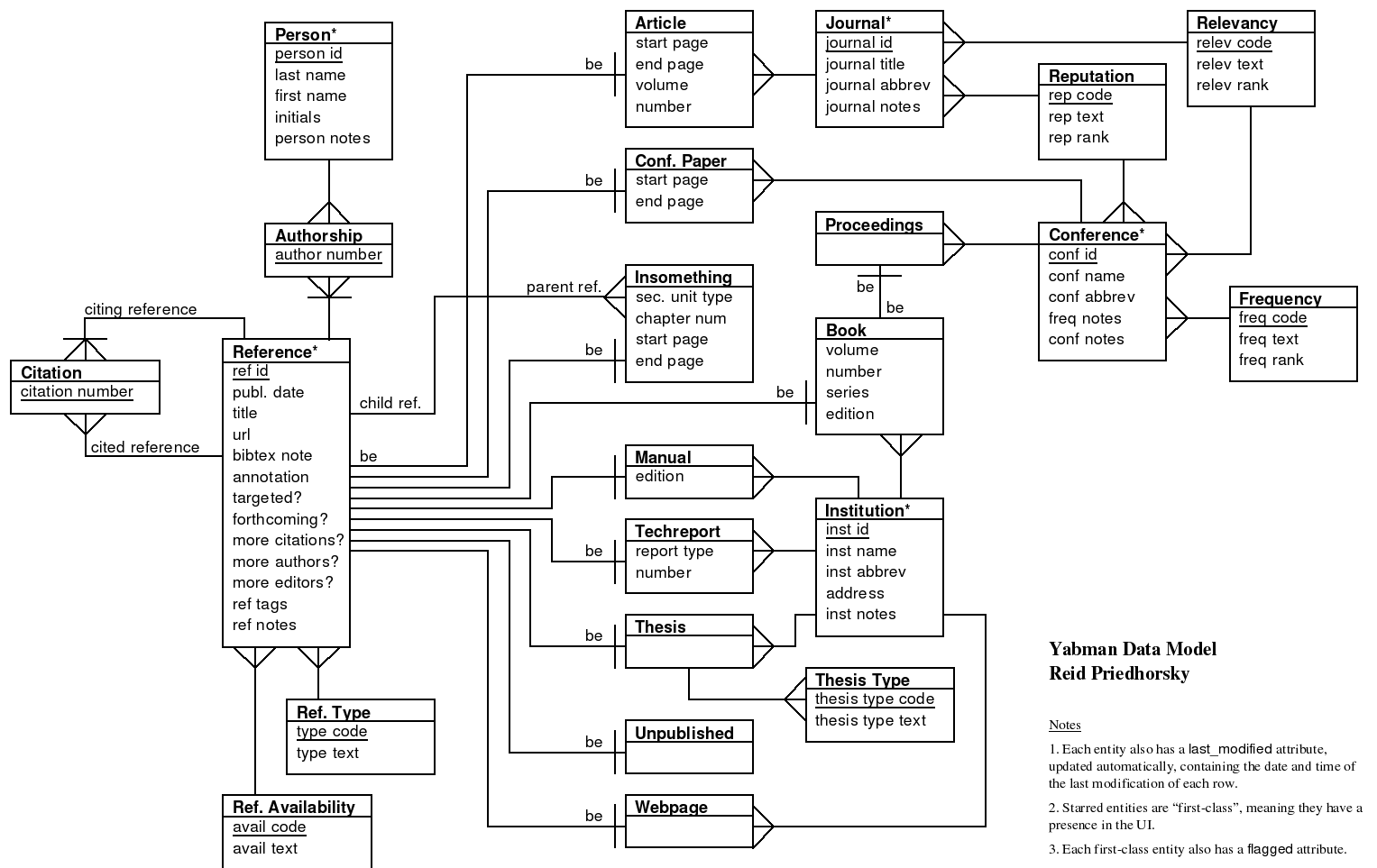
Thumbnail of the Yabman data model. Full-size: PNG, PDF (print on 11x17" paper). |
A good data model allows us to capture the meaning of the data we store and the relationships among those data -- in this case, bibliographic references, people, conferences, authorships of people on references, etc. The good data model enjoyed by Yabman disentangles the application from what it remembers: this facilitates easy import/export to various facilities and allows third-party tools to access the database in a meaningful way. Finally, it means that we can add new queries or views of data without being hamstrung by old decisions.
Yabman has a very good data model, carefully designed in the style of John Carlis. Other bibliography managers use ad-hoc data models which do not have these nice properties.
For example, suppose that I see several citations for papers written by a L. Fu, and I record these references in Yabman. Yabman remembers that the "L. Fu" on each paper is the same person. Later, I download the full text of the paper and discover that Mr. Fu is in fact Liping Fu -- I can make this change in one place and now every paper in my database "knows" Mr. Fu's full name. With other bibliography managers, I would have to search and replace each reference in my database -- this may be automated to some degree, but it's still awkward.
Let's suppose further that it turns out that there are two Liping Fus that write papers. Yabman is able to remember that these two men are separate people; other bibliography managers would get confused because the two names are identical. (We researchers do not have the benefit of a union guaranteeing that each person's name is different!)
Another example: suppose I'd like a report giving the reputation of each conference that Mr. Fu (either of them, or both) has published in. With Yabman, this is a simple SQL query; with other bibliography managers, much data groveling would be required.
The particular data model used for Yabman was reverse-engineered from the BibTeX documentation (Lamport, LaTeX: A Document Preparation System, Appendix B), and then augmented to support remembering a variety of other useful things and relationships.
You do not need to understand the nuances of the data model or Carlis' data modeling language to use or even meaningfully hack on Yabman. Just relax and enjoy the ride. :) If you do become interested, however, I suggest Mastering Data Modeling: A User-Driven Approach by Carlis and Maguire.
yabman-devs@lists.sf.net